Web Terminology and Characteristics
Web Mining is the process of Data Mining techniques to automatically discover and extract information from Web documents and services. The main purpose of web mining is discovering useful information from the World-Wide Web and its usage patterns. Applications of Web Mining:
- Web mining helps to improve the power of web search engine by classifying the web documents and identifying the web pages.
- It is used for Web Searching e.g., Google, Yahoo etc and Vertical Searching e.g., FatLens, Become etc.
- Web mining is used to predict user behavior.
- Web mining is very useful of a particular Website and e-service e.g., landing page optimization.
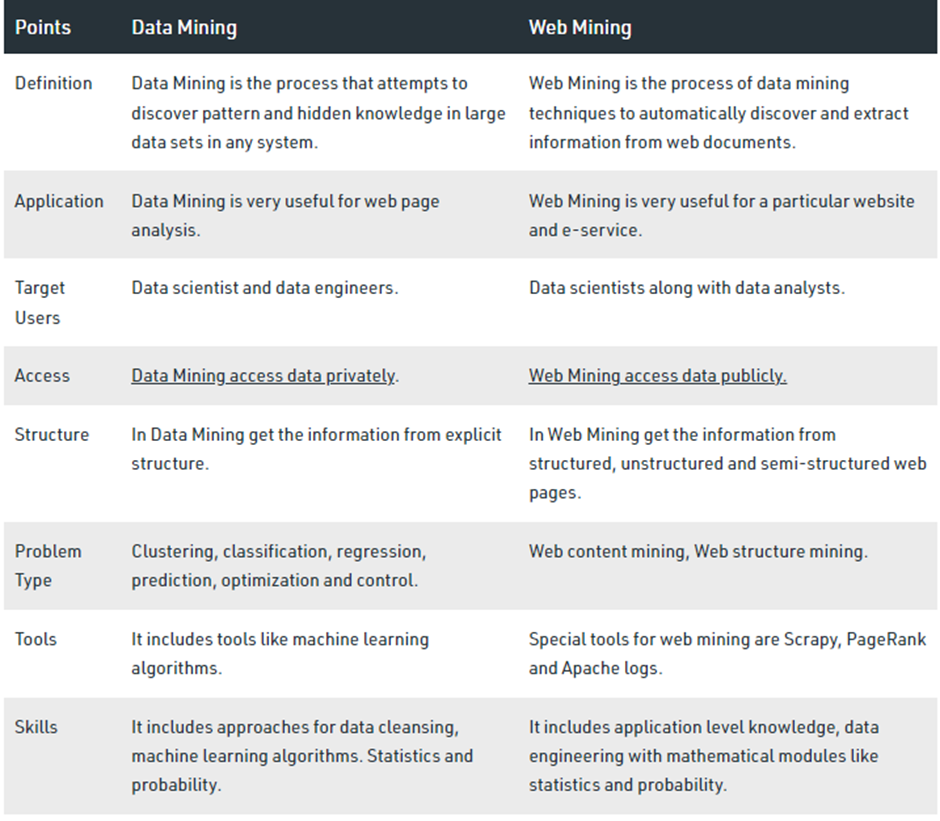
Web mining can be broadly divided into three different types of techniques of mining: Web Content Mining, Web Structure Mining, and Web Usage Mining. These are explained as following below.
- Web Content Mining: Web content mining is the application of extracting useful information from the content of the web documents. Web content consist of several types of data – text, image, audio, video etc. Content data is the group of facts that a web page is designed. It can provide effective and interesting patterns about user needs. Text documents are related to text mining, machine learning and natural language processing. This mining is also known as text mining. This type of mining performs scanning and mining of the text, images and groups of web pages according to the content of the input.
- Web Structure Mining: Web structure mining is the application of discovering structure information from the web. The structure of the web graph consists of web pages as nodes, and hyperlinks as edges connecting related pages. Structure mining basically shows the structured summary of a particular website. It identifies relationship between web pages linked by information or direct link connection. To determine the connection between two commercial websites, Web structure mining can be very useful.
- Web Usage Mining: Web usage mining is the application of identifying or discovering interesting usage patterns from large data sets. And these patterns enable you to understand the user behaviors or something like that. In web usage mining, user access data on the web and collect data in form of logs. So, Web usage mining is also called log mining.

Web Content Mining
Web content mining is referred to as text mining. Content mining is the browsing and mining of text, images, and graphs of a Web page to decide the relevance of the content to the search query.
This browsing is done after the clustering of web pages through structure mining and supports the results depending upon the method of relevance to the suggested query.
With a large amount of data that is available on the World Wide Web, content mining supports the results lists to search engines in order of largest applicability to the keywords in the query.
It can be defined as the phase of extracting essential data from standard language text. Some data that it can generate via text messages, files, emails, documents are written in common language text. Text mining can draw beneficial insights or patterns from such data.
Text mining is an automatic procedure that facilitates natural language processing to derive valuable insights from unstructured text. By changing data into information that devices can learn, text mining automates the phase of classifying texts by sentiment, subjects, and intent.
Text mining is directed toward specific data supported by the user search data in search engines. This enables the browsing of the entire Web to fetch the cluster content triggering the scanning of definite web pages within those clusters.
The results are pages transmitted to the search engines through the largest level of applicability to the lowest. Though the search engines can support connection to Web pages by the hundreds about the search content, this kind of web mining allows the reduction of irrelevant data. Web text mining is efficient when used in a content database dealing with definite subjects.
For instance, online universities need a library system to recall articles related to their frequent areas of study. This definite content database allows to pull only the data within those subjects, supporting the most specific outcomes of search queries in search engines.
This allowance of only the most relevant data being supported gives a larger quality of results. This increase in productivity is direct to the need for content mining of text and visuals. The need for this type of data mining is to gather, classify, organize and support the best possible data accessible on the WWW to the user requesting the data.
This tool is imperative to browsing the several HTML files, images, and text supported on Web pages. The resulting data is supported by the search engines in order of relevance giving higher productive results of every search.
Web Usage Mining
Web usage mining, a subset of Data Mining, is basically the extraction of various types of interesting data that is readily available and accessible in the ocean of huge web pages, Internet- or formally known as World Wide Web (WWW). Being one of the applications of data mining technique, it has helped to analyze user activities on different web pages and track them over a period of time. Basically, Web Usage Mining can be divided into 2 major subcategories based on web usage data.

1. Web Content Data: The common forms of web content data are HTML, web pages, images audio-video, etc. The main being the HTML format. Though it may differ from browser to browser the common basic layout/structure would be the same everywhere. Since it’s the most popular in web content data. XML and dynamic server pages like JSP, PHP, etc. are also various forms of web content data.
2. Web Structure Data: On a web page, there is content arranged according to HTML tags (which are known as intrapage structure information). The web pages usually have hyperlinks that connect the main webpage to the sub-web pages. This is called Inter-page structure information. So basically relationship/links describing the connection between webpages is web structure data.
3. Web Usage Data: The main source of data here is-Web Server and Application Server. It involves log data which is collected by the main above two mentioned sources. Log files are created when a user/customer interacts with a web page. The data in this type can be mainly categorized into three types based on the source it comes from:
- Server-side
- Client-side
- Proxy side.
There are other additional data sources also which include cookies, demographics, etc.
Types of Web Usage Mining based upon the Usage Data:
1. Web Server Data: The web server data generally includes the IP address, browser logs, proxy server logs, user profiles, etc. The user logs are being collected by the web server data.
2. Application Server Data: An added feature on the commercial application servers is to build applications on it. Tracking various business events and logging them into application server logs is mainly what application server data consists of.
3. Application-level data: There are various new kinds of events that can be there in an application. The logging feature enabled in them helps us get the past record of the events.
Advantages of Web Usage Mining
- Government agencies are benefited from this technology to overcome terrorism.
- Predictive capabilities of mining tools have helped identify various criminal activities.
- Customer Relationship is being better understood by the company with the aid of these mining tools. It helps them to satisfy the needs of the customer faster and efficiently.
Disadvantages of Web Usage Mining
- Privacy stands out as a major issue. Analyzing data for the benefit of customers is good. But using the same data for something else can be dangerous. Using it within the individual’s knowledge can pose a big threat to the company.
- Having no high ethical standards in a data mining company, two or more attributes can be combined to get some personal information of the user which again is not respectable.

1. Association Rules:The most used technique in Web usage mining is Association Rules. Basically, this technique focuses on relations among the web pages that frequently appear together in users’ sessions. The pages accessed together are always put together into a single server session. Association Rules help in the reconstruction of websites using the access logs. Access logs generally contain information about requests which are approaching the webserver. The major drawback of this technique is that having so many sets of rules produced together may result in some of the rules being completely inconsequential. They may not be used for future use too.
2. Classification: Classification is mainly to map a particular record to multiple predefined classes. The main target here in web usage mining is to develop that kind of profile of users/customers that are associated with a particular class/category. For this exact thing, one requires to extract the best features that will be best suitable for the associated class. Classification can be implemented by various algorithms – some of them include- Support vector machines, K-Nearest Neighbors, Logistic Regression, Decision Trees, etc. For example, having a track record of data of customers regarding their purchase history in the last 6 months the customer can be classified into frequent and non-frequent classes/categories. There can be multiclass also in other cases too.
3. Clustering: Clustering is a technique to group together a set of things having similar features/traits. There are mainly 2 types of clusters- the first one is the usage cluster and the second one is the page cluster. The clustering of pages can be readily performed based on the usage data. In usage-based clustering, items that are commonly accessed /purchased together can be automatically organized into groups. The clustering of users tends to establish groups of users exhibiting similar browsing patterns. In page clustering, the basic concept is to get information quickly over the web pages.
Applications of Web Usage Mining
1. Personalization of Web Content: The World Wide Web has a lot of information and is expanding very rapidly day by day. The big problem is that on an everyday basis the specific needs of people are increasing and they quite often don’t get that query result. So, a solution to this is web personalization. Web personalization may be defined as catering to the user’s need-based upon its navigational behavior tracking and their interests. Web Personalization includes recommender systems, check-box customization, etc. Recommender systems are popular and are used by many companies.

2. E-commerce: Web-usage Mining plays a very vital role in web-based companies. Since their ultimate focus is on Customer attraction, customer retention, cross-sales, etc. To build a strong relationship with the customer it is very necessary for the web-based company to rely on web usage mining where they can get a lot of insights about customer’s interests. Also, it tells the company about improving its web-design in some aspects.
3. Prefetching and Catching: Prefetching basically means loading of data before it is required to decrease the time waiting for that data hence the term ‘prefetch’. All the results which we get from web usage mining can be used to produce prefetching and caching strategies which in turn can highly reduce the server response time.
Web Structure Mining:
Web structure mining is a tool that can recognize the relationship between web pages linked by data or direct link connection. This structured data is discoverable by the provision of web structure schema through database techniques for Web pages.
This connection enables a search engine to pull data associated with a search query directly to the connecting Web page from the website the content rests upon. This completion takes place through the need of spiders scanning the websites, fetching the home page, then, and connecting the data through reference connection to bring forth the specific page including the desired information.
Web mining can widely be viewed as the application of adapted data mining methods to the web, whereas data mining is represented as the application of the algorithm to find patterns on mostly structured data fixed into a knowledge discovery process.
Web mining has a distinctive property to support a collection of multiple data types. The web has several aspects that yield multiple approaches for the mining process, such as web pages including text, web pages are connected via hyperlinks, and user activity can be monitored via web server logs.
Structure mining uses minimize two main problems of the World Wide Web because of its large amount of data. The first problem is irrelevant to search outcomes.
Relevance of search information becomes misconstrued due to the problem that search engines often only allow for low precision criteria.
The second problem is the inability to index the large amount of data supported on the Web. This generates a low amount of remembering with content mining. This minimization appears in part with the service of finding the model underlying the Web hyperlink structure supported by Web structure mining.
The objective of structure mining is to extract previously unknown relationships among web pages. This structure of data mining offers use for a business to connect the data of its website to allow navigation and cluster data into site maps.
This enables its users the ability to create the desired data through keyword relations and content mining. Hyperlink hierarchy is also decided to path the related data within the sites to the connection of competitor links and connection through search engines and third-party co-links. This allows clustering of linked Web pages to create the relationship of these pages.
On the World Wide Web, the use of structure mining allows the determination of the same architecture of Web pages by clustering through the identification of basic structure.
This data can be used to design the similarities of web content. The known similarities then support the ability to support or improve the data of a site to allow access of web-spiders in a higher ratio. The higher the number of Web crawlers, the more advantageous to the site due to related content to searches.


